
Pasar horas transcribiendo manualmente una tabla de un PDF escaneado chueco es un rito de iniciación corporativo que nadie quiere repetir. Extraer texto de imágenes ha sido, durante décadas, un dolor de cabeza técnico monumental. Los sistemas tradicionales requerían condiciones de laboratorio: iluminación perfecta, letras de imprenta impecables y un papel sin una sola arruga. Cuando la realidad golpeaba —un recibo manchado, una factura arrugada o notas escritas deprisa— el resultado era una sopa de letras incomprensible.
La llegada de los modelos de visión-lenguaje (VLMs) ha roto este paradigma. Ya no estamos limitados a enseñarle a una máquina a memorizar la forma de la letra «A». La inteligencia artificial contemporánea lee el documento casi como lo haría un humano. Observa la página completa, comprende el contexto de las frases y deduce que una palabra parcialmente borrada probablemente dice «Total» y no «T0ta1» porque está al final de una columna numérica.
Este salto cualitativo nos empuja directamente hacia el Procesamiento Inteligente de Documentos (IDP). Las empresas han dejado de buscar simples «conversores» para exigir motores de estructuración de datos. A lo largo de esta guía técnica, desarmaremos la arquitectura detrás del OCR impulsado por IA. Analizaremos por qué los métodos clásicos fallan en producción, cómo domesticar las alucinaciones de los modelos de lenguaje y, lo más importante, las metodologías exactas para transformar píxeles muertos en bases de datos consultables.
Tabla de Contenidos
- De Tesseract al IDP: La Evolución Tecnológica
- Anatomía de un Pipeline de Extracción Visual
- Casos de Uso Avanzados en la Industria
- El Peligro Oculto: Alucinaciones en Auditorías
- Criterios Técnicos para Elegir tu Stack de OCR
- Ingeniería de Prompts para Estructuración Estricta
- Guía de Implementación Práctica
- Errores Comunes al Procesar Documentos Complejos
- Preguntas Frecuentes sobre OCR con IA
De Tesseract al IDP: La Evolución Tecnológica
Para apreciar el nivel de sofisticación actual, necesitamos mirar hacia atrás. Los motores de reconocimiento óptico de caracteres (OCR) nacieron bajo una premisa matemática estricta: el mapeo de matrices de píxeles. Herramientas legendarias en el entorno del código abierto, como Tesseract OCR, construyeron los cimientos de la digitalización moderna. Su funcionamiento era lógico pero rígido.
Si el sistema esperaba encontrar la palabra «FACTURA», comparaba los grupos de píxeles oscuros de la imagen contra un diccionario visual preprogramado. El problema radicaba en la tolerancia al ruido. Un simple sello superpuesto sobre el texto, una rotación de tres grados en la hoja al pasar por el escáner, o un tipo de fuente ligeramente exótico, destruían la tasa de precisión. El sistema no leía; simplemente encajaba piezas de un rompecabezas visual.
El Procesamiento Inteligente de Documentos altera esta mecánica desde la raíz. La documentación técnica publicada por gigantes como IBM subraya que el IDP abandona el reconocimiento aislado de caracteres para abrazar el análisis jerárquico. Las redes neuronales convolucionales (CNN) trabajan en conjunto con transformadores visuales para mapear la semántica de la página entera.
| Especificación Técnica | OCR Tradicional (Basado en reglas) | OCR con IA (Modelos VLM / IDP) |
|---|---|---|
| Mecanismo Central | Binarización y coincidencia de patrones visuales. | Atención espacial y predicción de lenguaje natural. |
| Gestión de Ruido Visual | Extremadamente frágil. Falla ante marcas de agua o bajo contraste. | Robusto. Reconstruye caracteres dañados usando probabilidad contextual. |
| Extracción de Tablas | Requiere líneas divisorias perfectamente dibujadas. | Entiende columnas invisibles basándose en el espaciado (tablas sin bordes). |
| Caligrafía (ICR) | Nulo, salvo que se usen cajas de escritura delimitadas. | Excelente adaptación a cursivas, firmas y notas al margen. |
Esta capacidad de inferencia cambia las reglas del juego. Un modelo moderno sabe que después de la frase «Impuesto al Valor Agregado» probablemente siga un porcentaje o una cifra monetaria. Utiliza este conocimiento previo para sesgar positivamente su propia lectura óptica.
Anatomía de un Pipeline de Extracción Visual
Extraer texto con un nivel de confianza corporativo no es un evento de un solo clic. Detrás de la interfaz limpia de cualquier API moderna, ocurre una coreografía computacional compleja. Conocer estas fases te permite diagnosticar por qué ciertas imágenes fallan en tu flujo de trabajo.
Primero, el preprocesamiento dinámico. A diferencia del software antiguo que obligaba al usuario a limpiar la imagen en Photoshop, los modelos actuales aplican filtros de normalización internamente. Ajustan el sesgo (deskewing), corrigen la distorsión de la lente de las cámaras de los teléfonos móviles y aumentan el contraste de las sombras. Todo en milisegundos.
Luego entra en juego el análisis de diseño (Layout Analysis). Aquí es donde la IA traza «cajas delimitadoras» (bounding boxes) invisibles sobre la imagen. Clasifica cada bloque: esto es un párrafo, esto es un encabezado, esto es un gráfico que debe ignorarse, esto es una tabla de dos columnas. Esta fase evita que el texto se lea de izquierda a derecha de forma bruta, respetando el orden lógico de lectura humano, incluso en diseños de revistas de múltiples columnas.
Finalmente, ocurre la decodificación semántica. El texto dentro de las cajas se transcribe. Si hay una mancha de tinta tapando la mitad de una palabra en la frase «El paciente presenta fiebre y do_or de cabeza», el modelo de lenguaje integrado interviene. La visión artificial reporta incertidumbre en las letras centrales. El modelo de lenguaje evalúa el contexto médico e inyecta la palabra «dolor», reparando el daño visual sobre la marcha.
Casos de Uso Avanzados en la Industria
Cuando superas la barrera técnica de la digitalización, desbloqueas cuellos de botella operativos que consumían cientos de horas-hombre. La adopción de esta tecnología va mucho más allá de escanear un pasaporte en un aeropuerto.
El Fin de los Bloqueos Web (Scraping Visual)
Analistas de datos y periodistas de investigación a menudo chocan con plataformas cerradas. Portales gubernamentales, visores de PDF integrados o sitios web que ejecutan scripts para bloquear el clic derecho y la selección de texto. Intentar extraer datos del DOM de la página es inútil si el texto se renderiza como un canvas inerte. La solución actual es implacable: captura de pantalla al área visible y procesamiento visual directo. El modelo extrae el texto exacto, respetando saltos de línea y listas, ignorando por completo el código subyacente que intentaba protegerlo.
Digitalización Médica y Legal a Mano Alzada
Los expedientes judiciales y las recetas médicas comparten un rasgo trágico: caligrafía apresurada escrita bajo presión. Los sistemas de Reconocimiento Inteligente de Caracteres (ICR), ahora fusionados dentro del paraguas del IDP, identifican la inclinación particular de la mano de una persona a lo largo de un documento. Si la letra «r» del doctor parece una «v», la IA adapta su diccionario interno temporalmente para ese documento específico. Esto permite que una nota manuscrita sobre alergias a medicamentos se convierta en un registro electrónico estandarizado y busable instantáneamente.
Automatización de Cuentas por Pagar (Zero-Shot Extraction)
Las empresas grandes reciben facturas en cientos de plantillas distintas. Configurar una regla que diga «el total está en la esquina inferior derecha» deja de funcionar cuando un proveedor internacional envía una factura con el total en el margen superior izquierdo. El OCR impulsado por IA utiliza extracción «zero-shot». No necesitas entrenarlo con plantillas previas. La IA escanea la página, localiza semánticamente dónde habita el concepto de «monto a pagar», lo asocia con la moneda detectada y lo extrae. Este nivel de autonomía acelera el cierre contable de semanas a horas.
El Peligro Oculto: Alucinaciones en Auditorías
Sería irresponsable hablar de IA sin abordar su falla más crítica. La misma capacidad predictiva que hace a estos modelos tan potentes, los convierte en un riesgo monumental si no se supervisan. Hablamos del efecto de «caja negra» y el exceso de confianza del modelo.
Un escáner tradicional es honesto en su incompetencia. Si una grapa atraviesa un número de teléfono, te devuelve un bloque de texto con un agujero evidente o una serie de asteriscos. Sabes que falló. Un operador humano puede intervenir y teclear el número mirando el original.
Los Modelos de Lenguaje Grande (LLMs) tienen un ego algorítmico. Su objetivo principal es generar una respuesta coherente. Si un recibo fiscal está físicamente roto en la esquina inferior, justo donde debería estar el subtotal, el modelo se enfrenta a un vacío. En lugar de admitir la ilegibilidad, la IA nota que tiene los impuestos (ej. 16%) y tiene el Total Final. Rápidamente ejecuta un cálculo inverso matemático o, peor aún, inventa un número que parece estadísticamente plausible basándose en recibos similares.
El resultado es una tabla de datos perfectamente formateada, sin mensajes de error, que contiene información falsa. En un entorno de auditoría fiscal, inventar un subtotal es catastrófico. Para mitigar esto, los pipelines de producción avanzados exigen a la API que devuelva un «score de confianza» para cada campo extraído. Si el valor cae por debajo del 95%, se envía a una bandeja de revisión humana.
Criterios Técnicos para Elegir tu Stack de OCR
El mercado está inundado de herramientas que prometen extraer texto por arte de magia. Integrar la primera solución que aparezca en Google en tus procesos internos es un error estratégico. Debes auditar la herramienta bajo tres pilares innegociables: cumplimiento de privacidad, formato de salida estructural y retención temporal.
Si procesas documentos de identidad, historiales clínicos o contratos confidenciales, la regla de oro es la política de «cero retención». Muchos servicios gratuitos en la nube financian sus operaciones utilizando los documentos subidos por los usuarios para reentrenar sus futuras versiones de IA. Imagina que un modelo futuro empiece a autocompletar nombres basándose en la base de datos de clientes de tu empresa. Debes asegurar contratos comerciales que garanticen que la imagen se elimina de la RAM del servidor milisegundos después de la inferencia.
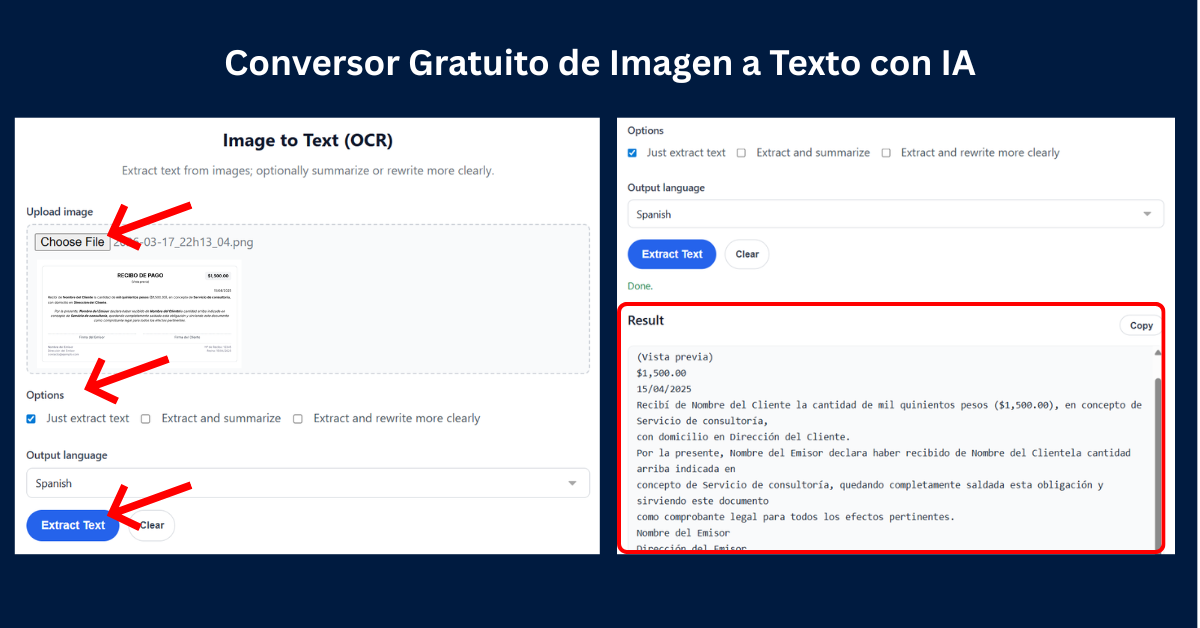
A nivel operativo, huir del «texto plano». Una excelente herramienta de visión artificial no escupe párrafos amontonados; respeta la jerarquía visual del documento original. Para integraciones rápidas, pruebas de concepto o tareas individuales que no requieren configuraciones de API complejas, utilizar un Conversor Gratuito de Imagen a Texto con IA especializado suele ser el primer paso ideal. Estas interfaces ya están optimizadas para aislar tablas y preservar la arquitectura del documento en formatos listos para copiar y pegar.
Ingeniería de Prompts para Estructuración Estricta
Aquí es donde la mayoría de los proyectos fracasan. Extraer el texto de la imagen es apenas el 50% del trabajo. El texto bruto (raw OCR text) suele venir acompañado de basura digital: números de página huérfanos, texto en letra pequeña de las condiciones legales, o caracteres extraños leídos del borde de la hoja.
Insertar esa masa de texto directamente en una base de datos SQL o en un ERP romperá tu esquema. Necesitas una capa intermedia de limpieza semántica. Esto se logra pasando el texto bruto a un modelo de lenguaje avanzado, pero atándolo de manos mediante un prompt restrictivo. Si le das libertad al modelo, empezará a conversar contigo («¡Claro! Aquí tienes los datos extraídos…»). No queremos conversación. Queremos una máquina de formateo estricta.
A continuación, tienes una arquitectura base para tu instrucción. Si planeas procesar miles de documentos y necesitas ajustar esto para modelos específicos de alta capacidad, te recomiendo refinar tu instrucción base pasando por el Generador de Prompts para Claude Gratis, el cual optimiza la redacción para forzar obediencia total.
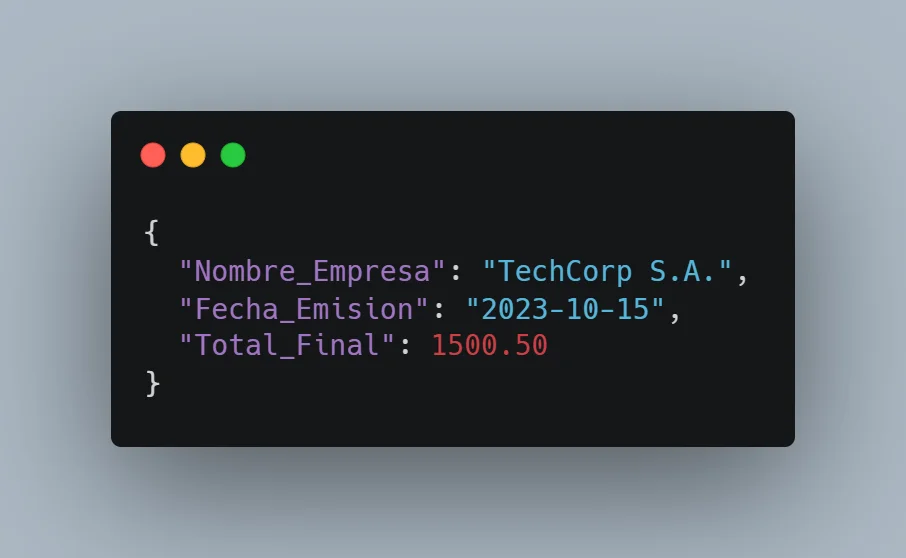
Actúa estrictamente como un parser de datos JSON. He extraído el siguiente texto en bruto de un documento físico escaneado mediante OCR. El texto contiene ruido de lectura.
Tu única tarea es limpiar los errores tipográficos obvios basados en el contexto comercial y mapear la información en el siguiente esquema JSON estricto.
Campos obligatorios a extraer:
1. "Nombre_Empresa": Nombre de la entidad emisora.
2. "Fecha_Emision": Convierte cualquier formato de fecha a "YYYY-MM-DD".
3. "Numero_Factura": Identificador del documento.
4. "Subtotal": Solo el valor numérico, formato float (ej. 1500.50).
5. "Impuestos": Solo el valor numérico, formato float.
6. "Total_Final": Solo el valor numérico, formato float.
Reglas críticas:
- NO incluyas saludos, confirmaciones, ni texto introductorio.
- Imprime ÚNICAMENTE el bloque JSON válido.
- Si un campo no existe en el texto, su valor DEBE ser estrictamente la palabra null (sin comillas). No inventes números.
- Ignora cualquier texto promocional, números de página o condiciones legales.
Texto bruto del OCR:[PEGA AQUÍ TU TEXTO BRUTO EXTRAÍDO DE LA IMAGEN]Esta estructura garantiza que tu pipeline no se rompa por un saludo inesperado de la IA. Aun así, los modelos pueden ser testarudos con formatos de fecha internacionales o símbolos de divisas pegados a los números. Si notas inconsistencias tras unas docenas de pruebas, puedes auditar tu instrucción utilizando un Analizador de Prompts IA para detectar qué línea de tu comando es demasiado ambigua y está permitiendo fugas de formato.
Guía de Implementación Práctica
Pasar de la teoría a un sistema funcionando en tu ordenador o servidor requiere orquestar varias piezas tecnológicas. Un pipeline de extracción visual profesional no es monolítico, se construye en fases modulares.
- Fase 1: Captura y Normalización de la Imagen. Las imágenes entran en diversos formatos (HEIC del iPhone, PNG de capturas web, PDFs de múltiples páginas). Debes convertirlas a un estándar ligero (como WebP o JPEG de alta calidad). Si envías una imagen de 15MB a una API de IA, los costos de ancho de banda y latencia se dispararán. Una resolución de 300 DPI suele ser el punto dulce entre velocidad y precisión.
- Fase 2: Llamada al Modelo de Visión. En lugar de usar una librería anticuada local, se envía la imagen codificada en base64 directamente a un VLM (Vision-Language Model). Dependiendo del nivel de privacidad requerido, esto puede ser un modelo alojado localmente en tus servidores (como LLaVA o Florence-2) o un servicio externo en la nube.
- Fase 3: Validación del Esquema (Pydantic / Zod). Nunca confíes ciegamente en el JSON que escupe la inteligencia artificial, por muy buen prompt que uses. Pasa la respuesta a través de una librería de validación de esquemas. Si el modelo devolvió
"Subtotal": "mil doscientos"en formato de texto en lugar del1200.00que exigía tu código, el validador detiene el proceso y lanza una alerta técnica en lugar de corromper tu base de datos. - Fase 4: Almacenamiento o Disparador de Acción. Una vez limpio y validado, el payload JSON se inyecta en tu CRM, Excel, o ERP. Para una automatización real, este evento puede disparar un webhook que notifique al equipo de contabilidad: «Nueva factura procesada y registrada.»
Errores Comunes al Procesar Documentos Complejos
La curva de aprendizaje en el IDP suele estar llena de tropiezos. El error más habitual de los desarrolladores junior es tratar todos los documentos por igual. Un ticket de supermercado arrugado no requiere el mismo nivel de procesamiento que una escritura notarial de cincuenta páginas.
Otro fallo crítico es ignorar el contexto multipágina. Si una factura tiene una tabla de conceptos que comienza en la página 1 y termina a mitad de la página 2, procesarlas como imágenes separadas y aisladas causará que el modelo asuma que son dos documentos distintos. Perderá la suma total o duplicará los datos del proveedor. La lógica de tu aplicación debe ser capaz de concatenar el texto extraído de todas las páginas antes de enviarlo a la fase final de limpieza semántica.
Finalmente, desestimar el «ruido de sal y pimienta» (los puntitos negros típicos de documentos escaneados repetidas veces). Aunque los modelos modernos son tolerantes, enviar basura visual exige más esfuerzo computacional a la red neuronal, lo que se traduce en mayor latencia de respuesta. Un simple filtro de limpieza previo en el código reducirá tus tiempos de extracción dramáticamente.
Preguntas Frecuentes sobre OCR con IA
¿Cuál es la diferencia entre OCR tradicional e IDP?
El OCR tradicional simplemente convierte píxeles de una imagen en letras de forma aislada sin entender el significado general, fallando frecuentemente ante el menor ruido visual o cambio tipográfico. El IDP (Procesamiento Inteligente de Documentos) combina reconocimiento óptico con redes neuronales y modelos de lenguaje grande. Esto le permite comprender el contexto, la estructura y la semántica del documento, logrando extraer datos organizados como tablas, facturas o formularios con una precisión y adaptabilidad incomparables.
¿El OCR con IA puede leer texto escrito a mano alzada?
Absolutamente. A diferencia de los escáneres de generaciones pasadas que requerían letras de imprenta perfectas y en casillas delimitadas, la visión artificial moderna (impulsada por redes neuronales y conocida como ICR) reconoce miles de estilos de caligrafía y escritura cursiva. Incluso si un garabato es visualmente ininteligible de forma aislada, el modelo utiliza el contexto gramatical del resto de la frase para deducir la palabra correcta.
¿Es seguro procesar facturas confidenciales con herramientas de IA en línea?
La seguridad depende enteramente de la arquitectura de la plataforma que elijas. Las herramientas empresariales de IDP y las API comerciales de pago operan bajo contratos estrictos y políticas de «cero retención de datos», eliminando el documento físico de la RAM inmediatamente tras la extracción. Sin embargo, subir documentos legales, PII (información de identificación personal) o estados financieros a interfaces públicas gratuitas de IA que utilizan datos de los usuarios para reentrenar sus modelos representa una vulnerabilidad de seguridad grave.
¿Cómo puedo copiar texto de una página web que tiene bloqueado el clic derecho?
El método más rápido y efectivo que no requiere conocimientos de código fuente es realizar una captura de pantalla del área que deseas respaldar o copiar. Posteriormente, subes esa imagen a un conversor de imagen a texto impulsado por inteligencia artificial. El modelo visual escaneará los píxeles de la captura y te devolverá el texto estructurado en segundos, evadiendo completamente cualquier restricción de JavaScript o bloqueos del navegador que la página original tuviera implementados.
¿Por qué la IA a veces inventa números al leer una factura borrosa?
Este comportamiento técnico se clasifica como una «alucinación». Los modelos de lenguaje grande son, en su núcleo, motores de predicción estadística diseñados para autocompletar patrones lógicos. Si analizas un recibo dañado donde falta el subtotal, pero los impuestos y el total son legibles, la IA detesta los vacíos. Intentará ejecutar una suposición matemática para rellenar la cifra faltante, priorizando la coherencia estructural sobre la fidelidad visual estricta. Es por esto que los auditores siempre requieren validaciones de confianza humana ante documentos sumamente degradados.
¿Puedo forzar a la IA a exportar los datos en Excel o tablas en lugar de párrafos?
Sí, y es la práctica recomendada. Durante la fase de solicitud o envío de la imagen al modelo, debes incluir un prompt de sistema que restrinja su formato de salida. Al indicarle que actúe como un analizador estructurado y exigirle que la salida sea estrictamente en formato JSON, Markdown o CSV, evitarás que te devuelva bloques de texto narrativo. Estos formatos estructurados pueden importarse directamente a Excel o cualquier software de base de datos sin fricción.

{kind=link}